Intel® FPGA SDK para OpenCL™ - Centro de asistencia
Aviso sobre la descontinuación de producto
Intel está descontinuando Intel® FPGA SDK para OpenCL,™ puede encontrar más información en la notificación de descontinuación del producto (PDN2219).
La página de soporte de Intel® FPGA SDK for OpenCL proporciona información sobre cómo emular, compilar y perfilar su kernel. También hay pautas sobre cómo optimizar su kernel, así como información sobre cómo depurar su sistema mientras ejecuta la aplicación host. Esta página está organizada en dos categorías principales según la plataforma de desarrollo: desarrollador de kernel para FPGA y desarrollador de código de host para CPU.
{kind=link}
Requisitos de software
Debe tener privilegios de administrador en el sistema de desarrollo para instalar los paquetes y controladores necesarios para el desarrollo del software host.
El sistema host debe ejecutar uno de los siguientes sistemas operativos Windows* y Linux* compatibles que aparecen en la página Compatibilidad con sistemas operativos .
Desarrolle su aplicación host para Intel® FPGA SDK for OpenCL™ mediante uno de los siguientes entornos de desarrollo:
Sistemas con sistema operativo Windows
- SDK de Intel FPGA para OpenCL
- Paquete de soporte de placa (BSP)
- Microsoft* Visual Studio Professional versión 2010 o posterior.
Sistemas con SO Linux
- SDK de Intel FPGA para OpenCL
- BSP
- RPM (Administrador de paquetes RPM; originalmente Red Hat Package Manager)
- Compilador C incluido con GCC
- Comando Perl versión 5 o posterior
1. Desarrollador del kernel
Interfaz de usuario del SDK
Intel® FPGA SDK para OpenCL™ proporciona dos modos de experiencia de desarrollo para los usuarios. Para los creadores de código, todas las herramientas están integradas en la GUI, lo que les permite diseñar, compilar y depurar el kernel. Por otro lado, las opciones de línea de comandos son para usuarios convencionales.
- Interfaz gráfica de usuario/generador de código: No disponible en este momento
- Opción de línea de comandos:
Aquí hay algunos comandos útiles para los desarrolladores de kernel:
aoc kernel.cl -o bin/kernel.aocx –board=<board_name>
- Compila kernel.cl archivo fuente en un archivo de programación FPGA (kernel.aocx) para la placa especificada por <board_name>; -o se utiliza para especificar el nombre del archivo de salida y la ubicación
aoc kernel.cl -o bin/kernel.aocx –board=<board_name> -march=emulator
- Construye un archivo aocx para emulación que se puede utilizar para probar la funcionalidad del kernel
aoc -list-boards
- Imprime una lista de placas y salidas disponibles
aoc -ayuda
- Imprime una lista completa de opciones de comandos aoc e información de ayuda para cada una de estas opciones
Versión de AOCL
- Muestra información de versión para la versión instalada de Intel FPGA SDK para OpenCL
Instalación de AOCL
- Instala controladores para su placa en el sistema host actual
Diagnóstico de AOCL
- Ejecuta el programa de prueba del proveedor de la placa para la placa
Programa AOCL
- Configura una nueva imagen de FPGA en la placa
Flash AOCL
- Inicializa el FPGA con una configuración de inicio especificada
Ayuda de AOCL
- Imprime una lista completa de opciones de comandos aocl e información de ayuda para cada una de estas opciones
Especificación de OpenCL
Compatibilidad con Khronos
Intel® FPGA SDK para OpenCL™ se basa en una especificación de Khronos publicada y es compatible con muchos proveedores que forman parte del grupo Khronos. Intel FPGA SDK para OpenCL ha superado el proceso de pruebas de conformidad de Khronos. Cumple con el estándar OpenCL 1.0 y proporciona los encabezados OpenCL 1.0 y OpenCL 2.0 del Grupo Khronos.
Atención: Actualmente, el SDK no es compatible con todas las interfaces de programación de aplicaciones (API) de OpenCL 2.0. Si utiliza los encabezados de OpenCL 2.0 y realiza una llamada a una API no compatible, la llamada devolverá un código de error para indicar que la API no es totalmente compatible.
El SDK de Intel FPGA para el tiempo de ejecución del host de OpenCL cumple con la capa de plataforma y la API de OpenCL con algunas aclaraciones y excepciones, que se pueden encontrar en la sección Estados de compatibilidad de las características de OpenCL de la Guía de programación de SDK de Intel FPGA para OpenCL.
Otros enlaces relacionados:
- Para obtener más información sobre OpenCL, visite la página Descripción general de OpenCL de Kronos Group .
- El estado de conformidad actual se puede encontrar en la página del Programa de adopción de Kronos Group .
- Para obtener más información sobre el estándar OpenCL 1.0, consulte La especificación OpenCL de Khronos.
Extensiones OpenCL
Canales (E/S o kernel)
Intel® FPGA SDK for OpenCL™ channel extension proporciona un mecanismo para pasar datos a kernels y sincronizar kernels con alta eficiencia y baja latencia. Utilice los siguientes enlaces para obtener más información sobre cómo implementar, utilizar y emular canales:
- Implementación de Intel FPGA SDK for OpenCL Channels Extension
- Uso de canales con copias de kernel
- Informe HTML: Conceptos de diseño de kernel - Canales
- Transferencia de datos a través de Intel FPGA SDK para canales OpenCL o canalizaciones OpenCL
- Requisito de varias colas de comandos en la implementación de canales o canalizaciones
Nota: Si desea aprovechar las capacidades de los canales pero tiene la capacidad de ejecutar su programa kernel utilizando otros SDK, implemente las canalizaciones de OpenCL. Para obtener más información sobre tuberías, consulte la siguiente sección sobre tuberías.
Tuberías
Intel FPGA SDK para OpenCL proporciona soporte preliminar para las funciones de canalización de OpenCL, que forman parte de la versión 2.0 de la especificación OpenCL. Proporcionan un mecanismo para pasar datos a los kernels y sincronizar kernels con alta eficiencia y baja latencia.
Intel FPGA SDK para la implementación de tuberías en OpenCL no es totalmente conforme con la versión 2.0 de la especificación OpenCL. El objetivo de la implementación de canalización del SDK es proporcionar una solución que funcione a la perfección en un dispositivo diferente compatible con OpenCL 2.0. Para habilitar tuberías en productos de Intel FPGA, su diseño debe cumplir ciertos requisitos.
Consulte los siguientes enlaces para obtener más información sobre cómo implementar las canalizaciones de OpenCL:
- Implementación de canalizaciones OpenCL
- Transferencia de datos a través de Intel FPGA SDK para canales OpenCL o canalizaciones OpenCL
- Requisito de varias colas de comandos en la implementación de canales o canalizaciones
Emulador
En un flujo de diseño de varios pasos, puede evaluar la funcionalidad de su kernel de OpenCL™ ejecutándolo en uno o varios dispositivos de emulación en un host x86-64 de Windows* o Linux*. La compilación del diseño para emulación tarda segundos en generar un archivo .aocx y le permite iterar en su diseño de manera más efectiva sin tener que pasar por las largas horas requeridas para la compilación completa.
Para sistemas Linux, el emulador ofrece compatibilidad con depuración simbólica. La depuración simbólica le permite localizar los orígenes de los errores funcionales en el código del kernel.
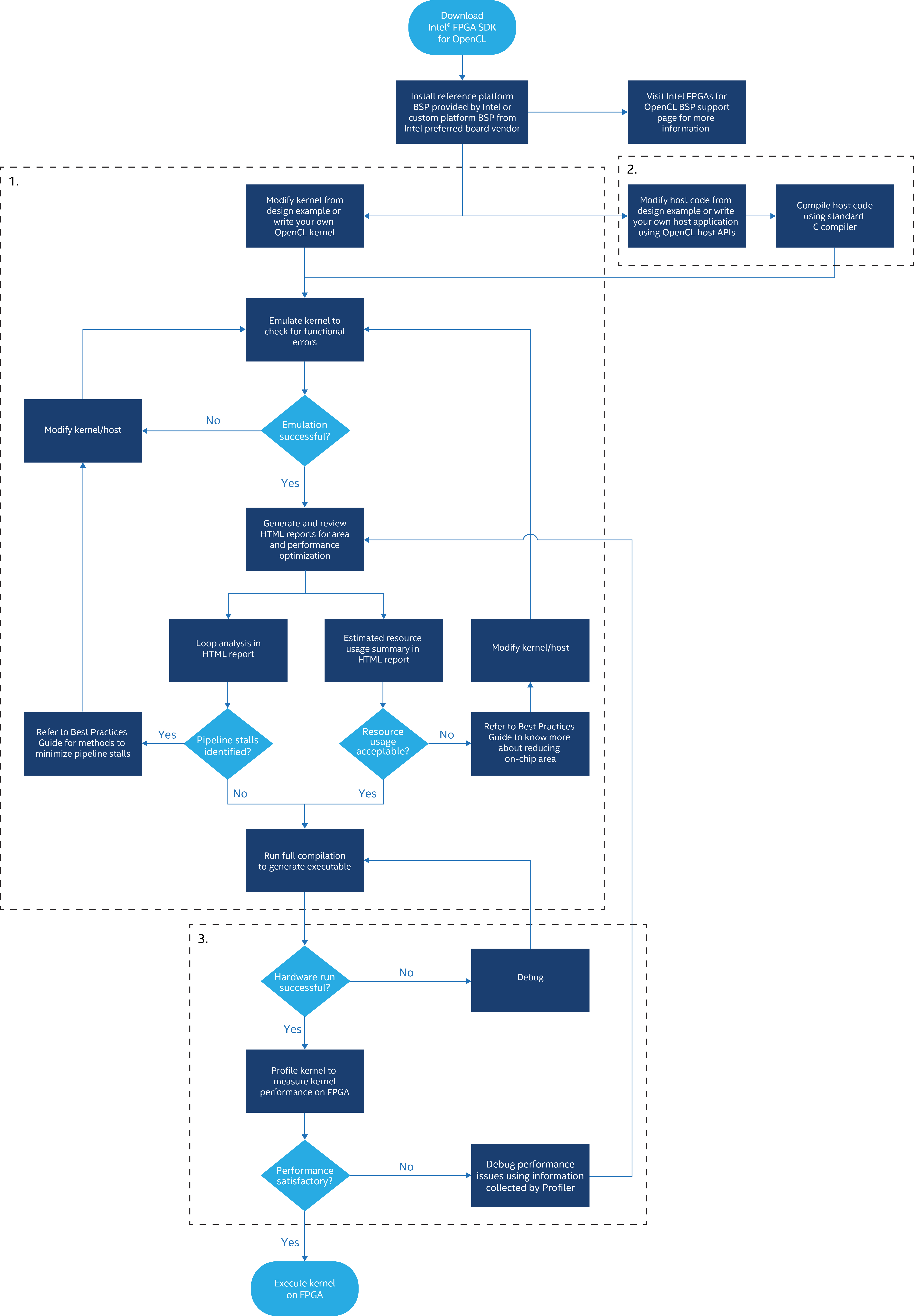
El siguiente enlace tiene una descripción general del flujo de diseño para los kernels de OpenCL e ilustra las diferentes etapas para las cuales puede emular su kernel.
SDK Intel® FPGA de varios pasos para el flujo de diseño de OpenCL
La sección Emulating and Debugging Your OpenCL Kernel de la Guía de programación contiene más detalles sobre las diferencias entre el funcionamiento del kernel en hardware y la emulación.
Otros enlaces relacionados:
- Emulación y depuración del kernel de OpenCL
- Emulación de canales de E/S
- Comprobación de la funcionalidad del tiempo de ejecución del host a través de la emulación (Windows)
- Verificación de la funcionalidad del tiempo de ejecución del host a través de la emulación (Linux)
Optimización
Con la tecnología SDK de Intel® FPGA para OpenCL™ Offline Compiler, no es necesario cambiar el kernel para que encaje de forma óptima en una arquitectura de hardware fija. En su lugar, el compilador sin conexión personaliza la arquitectura de hardware automáticamente para adaptarse a los requisitos del kernel.
En general, debe optimizar primero un kernel que se dirija a una sola unidad de cómputo. Después de optimizar esta unidad de cómputo, aumente el desempeño escalando el hardware para llenar el resto del FPGA. La huella de hardware del kernel se correlaciona con el tiempo que tarda la compilación de hardware. Por lo tanto, cuantas más optimizaciones pueda realizar con un espacio reducido (es decir, una sola unidad informática), más compilaciones de hardware podrá realizar en un período de tiempo determinado.
Optimización de OpenCL para Intel FPGAs
Para optimizar la implementación de su diseño y obtener el máximo rendimiento, comprenda su rendimiento máximo teórico y comprenda cuáles son sus limitaciones. Siga estos pasos:
- Comience con una simple implementación funcional conocida y buena.
- Utilice un emulador para validar la funcionalidad.
- Elimine o minimice los bloqueos de tuberías que se informan con el informe de optimización.
- Planifique el acceso a memoria para obtener un ancho de banda de memoria óptimo.
- Utilice un generador de perfiles para depurar los problemas de rendimiento.
El generador de perfiles ofrece más información sobre el desempeño del sistema, lo que le da instrucciones para optimizar aún más el algoritmo en el uso de la memoria.
Recuerde que, por FPGAs, cuantos más recursos se puedan asignar, más desenrollamiento, paralelización y mayor desempeño se podrá lograr.
Informes y recursos útiles para la optimización
Hay una serie de informes generados por el sistema disponibles para los usuarios. Estos informes ofrecen información sobre el código, el uso de recursos y sugerencias sobre dónde enfocarse para mejorar aún más el desempeño:
- Informe de análisis de bucle de un ejemplo de diseño de OpenCL
- Comprobación de la información sobre la replicación de memoria y los bloqueos
- Revisión de la información del área
- Informe HTML: Mensajes de informe de área
Optimización de memoria
Comprender los sistemas de memoria es crucial para implementar eficientemente una aplicación utilizando OpenCL.
Interconexión de memoria global
A diferencia de una GPU, una FPGA puede construir cualquier unidad de almacenamiento de carga personalizada (LSU) que sea más óptima para su aplicación. Como resultado, su capacidad para escribir código OpenCL que seleccione los tipos de LSU ideales para su aplicación podría ayudar a mejorar significativamente el desempeño de su diseño.
Para obtener más información, consulte la sección Interconexión de memoria global del SDK de Intel FPGA para obtener la Guía de mejores prácticas de OpenCL.
Memoria local
La memoria local es un sistema complejo. A diferencia de la arquitectura típica de GPU en la que hay diferentes niveles de cachés, una FPGA implementa la memoria local en bloques de memoria dedicados dentro del FPGA. Para obtener más información, consulte la sección Memoria local de la Guía de mejores prácticas de SDK de Intel FPGA para OpenCL.
Hay varias maneras en que se puede optimizar la memoria utilizada para mejorar el rendimiento general. Para obtener más información sobre algunas de las técnicas clave, consulte la sección Asignación de memoria alineada de la Guía de mejores prácticas de SDK de Intel FPGA para OpenCL.
Para obtener más información sobre las estrategias para mejorar la eficiencia del acceso a la memoria, consulte la sección Estrategias para mejorar la eficiencia del acceso a la memoria de la Guía de mejores prácticas de SDK de Intel FPGA para OpenCL.
Tuberías
Comprender los procesos es crucial para aprovechar el mejor desempeño de su implementación. El uso eficiente de las canalizaciones mejora directamente el rendimiento del desempeño. Para obtener más información, consulte la sección Canalizaciones de la Guía de mejores prácticas de Intel FPGA SDK for OpenCL.
Para obtener más información sobre la transferencia de datos, consulte la sección Transferencia de datos a través de Intel FPGA SDK para canales OpenCL u OpenCL Pipes de la Guía de mejores prácticas de SDK de Intel FPGA para OpenCL .
Puesto, ocupación, ancho de banda
Perfile su kernel para identificar cuellos de botella de desempeño. Para obtener más información sobre cómo la información de generación de perfiles le ayuda a identificar comportamientos deficientes de memoria o canal que conducen a un rendimiento insatisfactorio del kernel, consulte la sección Elaboración de perfiles de su kernel para identificar cuellos de botella de rendimiento de la Guía de mejores prácticas de SDK de Intel FPGA para OpenCL.
Optimización de bucle
Algunas técnicas para optimizar los bucles son:
Para obtener algunos consejos sobre cómo eliminar dependencias controladas por bucle en varios escenarios para un solo núcleo de elemento de trabajo, consulte la sección Eliminación de la dependencia llevada por bucle de la Guía de mejores prácticas de SDK de Intel FPGA para OpenCL.
Para obtener más información sobre la optimización de operaciones de punto flotante, consulte la sección Optimización de operaciones de punto flotante de la Guía de mejores prácticas de SDK de Intel FPGA para OpenCL.
Optimización de área
El uso del área es una consideración de diseño importante si sus kernels OpenCL son ejecutables en FPGAs de diferentes tamaños. Cuando diseñe su aplicación en OpenCL, Intel recomienda que siga ciertas estrategias de diseño para optimizar el uso del área de hardware.
La optimización del desempeño del kernel generalmente requiere recursos FPGA adicionales. Por el contrario, la optimización del área a menudo resulta en una disminución del rendimiento. Durante la optimización del kernel, Intel recomienda que ejecute varias versiones del kernel en la placa FPGA para determinar la estrategia de programación del kernel que genere el mejor equilibrio entre tamaño y desempeño.
Para obtener más información sobre las estrategias para optimizar el uso del área de FPGA, consulte la sección Estrategias para optimizar el uso del área de FPGA de la Guía de mejores prácticas de Intel FPGA SDK for OpenCL.
Ejemplos de diseño de referencia
Algunos ejemplos de diseño que ilustran las técnicas de optimización son los siguientes:
Ejemplo de diseño de multiplicación de matriz
Este ejemplo muestra la optimización de la operación fundamental de multiplicación de matrices utilizando mosaico de bucle para aprovechar la reutilización de datos inherente al cálculo.
Este ejemplo ilustra:
- Optimizaciones de punto flotante de precisión simple
- Búfer de memoria local
- Optimizaciones de compilación (desenrollado de bucles, atributo num_simd_work_items)
- Optimizaciones de punto flotante
- Ejecución de múltiples dispositivos
Ejemplo de diseño de filtro FIR en dominio del tiempo
Este ejemplo de diseño implementa el análisis de referencia del filtro de respuesta finita al impulso (FIR) en el dominio del tiempo del conjunto de análisis de referencia HPEC Challenge.
Este diseño es un excelente ejemplo de cómo FPGAs puede proporcionar un desempeño mucho mejor que una arquitectura de GPU para filtros FIR de punto flotante.
Este ejemplo ilustra:
- Optimizaciones de punto flotante de precisión simple
- Implementación eficiente de búfer de ventana deslizante 1D
- Métodos de optimización de kernel de un solo elemento de trabajo
Ejemplo de diseño de reducción de escala de video
Este ejemplo de diseño implementa un downscaler de video que toma video de entrada de 1080p y genera video de 720p a 110 fotogramas por segundo. En este ejemplo se usan varios kernels para leer y escribir en la memoria global de manera eficiente.
Este ejemplo ilustra
- Canales de kernel
- Múltiples núcleos simultáneos
- Canales de kernel a kernel
- Patrón de diseño de ventana corredera
- Optimizaciones de patrones de acceso a la memoria
Ejemplo de diseño de flujo óptico
Este ejemplo de diseño es una implementación de OpenCL del algoritmo de flujo óptico Lucas Kanade. Se muestra que una versión densa, no iterativa y no piramidal con un tamaño de ventana de 52x52 se ejecuta a más de 80 fotogramas por segundo en el kit de desarrollo de SoC Cyclone® V.
Este ejemplo ilustra:
- Kernel de elemento de trabajo único
- Patrón de diseño de ventana corredera
- Técnicas de reducción del uso de recursos
- Salida visual
Entrenamiento
La capacitación en línea específica para la optimización de OpenCL con ejemplos de diseño está disponible en:
- Técnicas de optimización de OpenCL: ejemplo de algoritmo de procesamiento de imágenes
- Técnicas de optimización de OpenCL: ejemplo de algoritmo hash seguro
Referencias
Perfiles
En un flujo de diseño de varios pasos, si el desempeño estimado del kernel de la emulación es aceptable, puede optar por recopilar información sobre cómo funciona su diseño mientras se ejecuta en el FPGA.
Puede indicar al SDK de Intel® FPGA para OpenCL™ Offline Compiler que instrumente los contadores de rendimiento en el código Verilog del archivo .aocx con la opción -profile. Durante la ejecución, el SDK de Intel FPGA para OpenCL Profiler mide e informa los datos de rendimiento que se recopilan durante la ejecución del kernel de OpenCL en la FPGA. A continuación, puede revisar los datos de desempeño en la GUI del generador de perfiles.
La sección Elaboración de perfiles de su kernel OpenCL de la Guía de programación de Intel FPGA SDK for OpenCL contiene más información sobre cómo perfilar su kernel .
Cómo analizar los datos de elaboración de perfiles
La información de generación de perfiles le ayuda a identificar comportamientos deficientes de memoria o canal que conducen a un rendimiento insatisfactorio del kernel. La sección Perfil de su kernel para identificar cuellos de botella de rendimiento de la Guía de mejores prácticas de SDK de Intel FPGA para OpenCL contiene información más detallada sobre la GUI de Dynamic Profiler y cómo interpretar los datos de generación de perfiles, como bloqueo, ancho de banda, aciertos de caché, etc. También contiene un análisis del generador de perfiles de varios escenarios de ejemplo de diseño de OpenCL.
2. Desarrollador de código de host
Bibliotecas de host en tiempo de ejecución
Intel® FPGA SDK for OpenCL proporciona un compilador y herramientas para crear y ejecutar aplicaciones OpenCL™ destinadas a Intel FPGA productos.
Si solo necesita el SDK de Intel FPGA para la funcionalidad de implementación del kernel de OpenCL, descargue e instale el entorno de tiempo de ejecución de Intel FPGA (RTE) para OpenCL.
RTE es un subconjunto de Intel FPGA SDK para OpenCL. A diferencia del SDK, que proporciona un entorno que permite el desarrollo y la implementación de programas de kernel OpenCL, RTE proporciona herramientas y componentes de tiempo de ejecución que le permiten crear y ejecutar un programa host, y ejecutar programas de kernel OpenCL precompilados en placas aceleradoras de destino.
No instale el SDK y la RTE en el mismo sistema host. El SDK ya contiene el RTE.
Utilidades y bibliotecas de tiempo de ejecución del host
RTE for OpenCL proporciona utilidades, bibliotecas de tiempo de ejecución de host, controladores y bibliotecas y archivos específicos de RTE.
- La utilidad RTE incluye comandos que puede invocar para realizar tareas de alto nivel. Las utilidades RTE son un subconjunto de Intel FPGA SDK for OpenCL utilities
- El tiempo de ejecución del host proporciona la API de la plataforma host OpenCL y la API de tiempo de ejecución para su aplicación host OpenCL
El tiempo de ejecución del host consta de las siguientes bibliotecas:
- Las bibliotecas vinculadas estáticamente proporcionan API de host OpenCL, abstracciones de hardware y bibliotecas auxiliares
- Las bibliotecas de vínculos dinámicos (DLL) proporcionan abstracciones de hardware y bibliotecas auxiliares
Para obtener más información sobre las utilidades y las bibliotecas de tiempo de ejecución de host, consulte la sección Contenido de la Intel FPGA RTE para OpenCL de la Guía de inicio de Intel FPGA RTE para OpenCL .
Transmisión de datos (canal host)
Ahora puede reducir significativamente la latencia del sistema mediante el uso de canales host que permiten la transmisión de datos desde el host para transmitirlos directamente al kernel de la FPGA a través de la interfaz PCIe*, sin pasar por el controlador de memoria. El kernel FPGA puede comenzar a procesar los datos inmediatamente y no tiene que esperar a que se complete la transferencia de datos. Los canales de host son compatibles con las interfaces de programación de aplicaciones (API) de tiempo de ejecución de OpenCL e incluyen compatibilidad con emulación.
Para obtener más detalles sobre los canales host y la compatibilidad con la emulación, consulte la sección Emulación de canales de E/S de la Guía de programación de SDK de Intel® FPGA para OpenCL™.
Relleno
La elaboración de perfiles le permite saber dónde pasó su tiempo su programa y cuáles son las diferentes funciones que se llaman. Esta información muestra qué parte del programa se está ejecutando más lentamente de lo esperado que podría necesitar una reescritura para una ejecución más rápida del programa. También puede decirle qué funciones se están llamando con más o menos frecuencia de lo que esperaba.
GPROF
El gprof es una herramienta de código abierto disponible en los sistemas operativos Linux* para elaborar perfiles del código fuente. Funciona en muestreo basado en el tiempo. Durante los intervalos, el contador de programa es interrogado para decidir en qué punto del código ha llegado la ejecución.
Para utilizar el gprof, vuelva a compilar el código fuente mediante el indicador de generación de perfiles del compilador -pg
Ejecute los archivos ejecutables para generar los archivos que contienen información de generación de perfiles:
Se genera un archivo específico llamado "gmon.out" que contiene toda la información que la herramienta gprof requiere para producir datos de perfiles legibles por humanos. Por lo tanto, ahora use la herramienta gprof de la siguiente manera:
$ gprof código fuente gmon.out > profile_data.txt
profile_data.txt es el archivo que contiene la información que la herramienta GPROF utiliza para producir datos de creación de perfiles legibles por humanos. Esto contiene dos partes: perfil plano y gráfico de llamadas.
El perfil plano muestra cuánto tiempo pasó el programa en cada función y cuántas veces se llamó a esa función.
El gráfico de llamadas muestra, para cada función, qué funciones la llamaron, a qué otras funciones llamó y cuántas veces. También hay una estimación de cuánto tiempo se pasó en las subrutinas de cada función.
Más información sobre el uso de gprof para la elaboración de perfiles está disponible en el sitio web de GNU.
Amplificador Intel® VTune™
® Intel VTune™ Amplifier que se utiliza para elaborar perfiles le ayuda a acelerar y optimizar la ejecución de su código en plataformas integradas Linux, sistemas Android* o Windows*, proporcionando los siguientes tipos de análisis:
- Análisis de rendimiento: Encuentre cuellos de botella de código serial y paralelo, analice las opciones de algoritmos y el uso del motor de GPU, y comprenda dónde y cómo su aplicación puede beneficiarse de los recursos de hardware disponibles
- Intel Energy Profiler análisis: Analice los eventos de energía e identifique aquellos que desperdician energía
Para obtener más información sobre Intel V-tune Amplifier, visite el sitio web Getting Started with Intel VTune Amplifier 2018 for Linux OS .
Multithreading
Los subprocesos múltiples canalizados de host OpenCL™ proporcionan un marco para lograr un alto rendimiento para algoritmos en los que se debe procesar una gran cantidad de datos de entrada y el proceso de cada dato debe realizarse en orden secuencial. Una de las mejores aplicaciones de este marco se encuentra en plataformas heterogéneas donde se utiliza hardware o plataforma de alto rendimiento para acelerar la parte de la aplicación que más tiempo consume. Las partes restantes del algoritmo deben ejecutarse en un orden secuencial en otras plataformas, como CPU, para preparar los datos de entrada para la tarea acelerada o para usar la salida de esa tarea para preparar la salida final. En este escenario, aunque el rendimiento del algoritmo se acelera parcialmente, el rendimiento total del sistema es mucho menor debido a la naturaleza secuencial del algoritmo original.
En esta nota de aplicación AN 831: Intel FPGA SDK for OpenCL Host Pipelined Multithread, se propone un nuevo marco canalizado para un diseño de alto rendimiento. Este marco es óptimo para procesar grandes datos de entrada a través de algoritmos donde la dependencia de datos fuerza la ejecución secuencial de todas las etapas o tareas del algoritmo.
FPGA Iniciación desde el host
FPGAs son muy utilizados en el espacio de aceleración. OpenCL tiene una forma específica de ser utilizado por la CPU para descargar tareas a FPGA. El archivo adjunto a continuación contiene los pasos comunes de inicialización necesarios para que el código de host inicie el kernel FPGA. Descargue aquí el archivo que contiene los pasos de inicialización.
Se puede llamar a la función init() desde la función main() para inicializar el FPGA. El código primero encuentra el dispositivo en el que se ejecutará el kernel, y luego lo programa con el aocx suministrado en el mismo directorio que el host execuatable. Después de los pasos de inicialización en el código, el usuario debe establecer los argumentos del kernel de acuerdo con sus necesidades de diseño.
También hay una función cleanup() que libera los recursos después de ejecutar el kernel.
3. Depurar
Emulación
El SDK de Intel® FPGA para el emulador OpenCL™ se puede utilizar para comprobar la funcionalidad del kernel. El usuario también puede depurar la funcionalidad del kernel de OpenCL como parte de la aplicación host en sistemas Linux*. La función de depuración proporcionada con Intel FPGA SDK for OpenCL Emulator le permite hacerlo.
Para obtener más información, consulte estas secciones de la Guía de programación de SDK de Intel FPGA para OpenCL:
Perfiles
Para obtener más información sobre la creación de perfiles, consulte estas secciones en la Guía de programación de SDK de Intel® FPGA para OpenCL™:
Variables de depuración de tiempo de ejecución |
|
|---|---|
| Hay ciertas variables de entorno que se pueden configurar para obtener más información de depuración mientras se ejecuta la aplicación host. Estas son Intel® FPGA SDK para variables de entorno específicas de OpenCL™, que pueden ayudar a diagnosticar problemas con diseños de plataforma personalizados. En la tabla siguiente se enumeran todas estas variables de entorno y se describen en detalle. | |
| Título de variable de entorno | Descripción |
ACL_HAL_DEBUG |
Establezca esta variable en un valor de 1 a 5 para aumentar la salida de depuración de la capa de abstracción de hardware (HAL), que interactúa directamente con la capa MMD. |
ACL_PCIE_DEBUG |
Establezca esta variable en un valor de 1 a 10.000 para aumentar la salida de depuración del MMD. Esta configuración de variable es útil para confirmar que el registro de ID de versión se leyó correctamente y que los núcleos IP de UniPHY están calibrados. |
ACL_PCIE_JTAG_CABLE |
Establezca esta variable para reemplazar el argumento de quartus_pgm predeterminado que especifica el número de cable. El valor predeterminado es cable 1. Si hay varios cables de descarga Intel® FPGA, puede especificar un cable determinado configurando esta variable. |
ACL_PCIE_JTAG_DEVICE_INDEX |
Establezca esta variable para reemplazar el argumento de quartus_pgm predeterminado que especifica el índice de dispositivo FPGA. De forma predeterminada, esta variable tiene un valor de 1. Si el FPGA no es el primer dispositivo de la cadena JTAG, puede personalizar el valor. |
ACL_PCIE_USE_JTAG_PROGRAMMING |
Establezca esta variable para forzar al MMD a reprogramar la FPGA utilizando el cable JTAG en lugar de una reconfiguración parcial. |
ACL_PCIE_DMA_USE_MSI |
Establezca esta variable si desea utilizar MSI para transferencias de acceso directo a memoria (DMA) en el sistema operativo Windows*. |
Herramienta de diagnóstico para Intel® FPGA SDK para OpenCL™
La herramienta de diagnóstico para Intel FPGA SDK para OpenCL ayuda a diagnosticar y resolver varios problemas de instalación / configuración, problemas de hardware y software que surgen al trabajar con Intel FPGA SDK para OpenCL. La herramienta realiza pruebas de instalación, pruebas de dispositivos y pruebas de enlaces. Para obtener más información sobre la herramienta, consulte esta presentación. Para usar la herramienta, descárguela desde aquí.
Otras técnicas de depuración
Debido a un bucle en el programa host, los usuarios pueden experimentar que el sistema OpenCL™ se ralentiza mientras lo ejecutan. Para conocer más detalles sobre este escenario, consulte la sección Depurar el sistema OpenCL que se está ralentizando gradualmente de la Guía de programación de SDK de Intel® FPGA para OpenCL.
Intel Code Builder for OpenCL es una herramienta de desarrollo de software disponible como parte de Intel FPGA SDK for OpenCL. Proporciona un conjunto de complementos de Microsoft* Visual Studio y Eclipse que habilitan capacidades para crear, compilar, depurar y analizar aplicaciones de Windows* y Linux* aceleradas con OpenCL. Para obtener más información, consulte la sección Desarrollo/depuración de aplicaciones OpenCL con Intel Code Builder para OpenCL de la Guía de programación de SDK de Intel FPGA para OpenCL.
Solución de base de datos de conocimiento
Intel® Arria® 10 dispositivos
Intel® Stratix® 10 dispositivos
Recursos adicionales
Aquí hay algunos enlaces adicionales de la Comunidad Intel FPGA para temas específicos relacionados con las etapas de diseño y ejecución:
4. Formación disponible
Cursos de Entrenamiento
Vea los siguientes cursos de entrenamiento de OpenCL™:
- Introducción a la computación en paralelo con OpenCL™ en Intel® FPGAs
- Escritura de OpenCL en Intel FPGAs
- Ejecución de OpenCL en Intel FPGAs
- Otros cursos de entrenamiento de OpenCL
- Creación de un módulo RTL para Intel® FPGA SDK para OpenCL™
- Creación de plataformas personalizadas para Intel® FPGA SDK para OpenCL:™ Aspectos básicos de BSP
- Creación de plataformas personalizadas para Intel® FPGA SDK para OpenCL:™ modificación de una plataforma de referencia
Videos rápidos de OpenCL™ |
|
|---|---|
Título del video |
Descripción del video |
Cómo ejecutar Hello World y (otros programas) con OpenCL™ en Cyclone® V SoC con Windows* Parte 1 |
Este video describe el procedimiento listo para usar para ejecutar dos aplicaciones, OpenCL HelloWorld y OpenCL™ fast Fourier transform (FFT) en el SoC Cyclone® V utilizando una máquina Windows*. |
Cómo ejecutar Hello World y (otros programas) con OpenCL en Cyclone V SoC usando Windows Parte 2 |
Este video describe el procedimiento listo para usar para ejecutar dos aplicaciones, OpenCL HelloWorld y OpenCL FFT en el SoC Cyclone V usando una máquina Windows. |
Cómo ejecutar Hello World y (otros programas) con OpenCL en Cyclone V SoC usando Windows Parte 3 |
Este video describe el procedimiento listo para usar para ejecutar dos aplicaciones, OpenCL HelloWorld y OpenCL FFT en el SoC Cyclone V usando una máquina Windows. |
Cómo ejecutar Hello World y (otros programas) con OpenCL en Cyclone V SoC usando Windows Parte 4 |
Este video describe el procedimiento listo para usar para ejecutar dos aplicaciones, OpenCL HelloWorld y OpenCL FFT en el SoC Cyclone V usando una máquina Windows. |
Cómo ejecutar Hello World y (Otros programas) con OpenCL en Cyclone V SoC usando Windows Parte 5 |
Este video describe el procedimiento listo para usar para ejecutar dos aplicaciones, OpenCL HelloWorld y OpenCL FFT en el SoC Cyclone V usando una máquina Windows. |
Cómo empaquetar módulos/diseños personalizados de Verilog como bibliotecas OpenCL |
El video discute por qué los clientes podrían usar esta característica para tener sus bloques de procesamiento personalizados (RTL) en el código del kernel OpenCL. El video explica el ejemplo de diseño, como los archivos makefiles y config, y explica el flujo de compilación. El video también muestra una demostración del ejemplo de diseño. |
OpenCL en Altera® SoC FPGA (Linux* Host) – Parte 1 – Descarga y configuración de herramientas |
Este video le muestra cómo descargar, instalar y configurar las herramientas necesarias para desarrollar kernels OpenCL y códigos de host dirigidos Altera® FPGAs de SoC. |
Este video muestra cómo descargar y compilar una aplicación OpenCL de ejemplo dirigida al emulador que está integrado en OpenCL. |
|
Este video le muestra cómo compilar el kernel de OpenCL y el código de host dirigidos al FPGA y al procesador del FPGA de sistema integrado en chip Cyclone V. |
|
OpenCL en Altera SoC FPGA (Linux Host) – Parte 4 – Configuración del entorno de tiempo de ejecución |
Este video muestra cómo configurar la placa de sistema integrado en chip Cyclone V para ejecutar el ejemplo de OpenCL y ejecutar el código de host y el kernel en la placa. |
El contenido de esta página es una combinación de la traducción humana y automática del contenido original en inglés. Este contenido se ofrece únicamente para su comodidad como información general y no debe considerarse completa o precisa. Si hay alguna contradicción entre la versión en inglés de esta página y la traducción, prevalecerá la versión en inglés. Consulte la versión en inglés de esta página.