![]() 要点综述
要点综述
LLT 和其他时间敏感型应用是 FPGA 加速的理想用例。为满足该市场的需求,菲数科技开发出基于 FPGA 的 FA728Q 加速卡。FA728Q 加速平台为最终用户提供了强大的 FPGA 资源、丰富的存储容量和易于使用的接口。为加速、简化并标准化加速板的开发,菲数科技采用了 OFS 基础设施,该基础设施提供了强大的方法,支持以“量身定制”方式加速开发 FPGA 解决方案。利用 OFS 基础设施,菲数科技可将其 TCP/IP 分载引擎集成到开源基础 FIM(通常称为 FPGA “shell”)中。
背景和挑战
LLT 是一种现代化做法,即以电子方式执行金融证券交易,并尽可能缩短订单录入和订单执行之间的时间延迟。大型投资银行、对冲基金和其他金融机构通常采用这一方法。过去,交易均以手动方式进行,而非电子方式,交易的执行时间从数秒到数分钟不等。但是,随着硬件和相应软件技术的进步,系统可编程为根据某些市场信号和动向自动作出买入或卖出决策,从而将交易执行时间缩短到几毫秒。近年来,随着基于 FPGA 加速产品的更广泛普及,交易时间进一步缩短到微秒级或亚微秒级。
与此同时,LLT 系统越来越依赖于每家交易公司特定交易策略所独有的复杂交易算法模型来进行订单簿交互。解决方案需要通用处理器和专用协处理器计算,以满足交易机构的功耗和性能要求,例如在异构计算中。FPGA 非常适合实施量身定制的交易算法;但是,随着 FPGA 家族的改进和演变,对这种硬件加速设备进行编程可能十分耗时,且难以进行迁移。
菲数科技是一家总部位于中国的公司,该公司正跃跃欲试,力求满足数据中心异构加速和高性能计算方面的需求,包括 LLT 细分市场。他们将基于 FPGA 的硬件加速器平台、FPGA 加速知识产权 (IP) 功能和基于 FPGA 的平台设计服务推向市场。
解决方案
为满足 LLT 应用的低延迟、标准化和可移植要求,菲数科技开发了 FA728Q 加速卡,该卡可将集成式 TCP/IP 分载引擎实例化。为此,菲数科技修改了 OFS 开源版本中提供的基础 FIM。由于采用了可组合架构和“量身定制”方法,OFS 可支持他们将算法轻松移植到 FA728Q 加速卡,同时,仅需最低程度的修改,即可利用所提供的其余基础设施,包括 OFS 软件驱动程序和库。
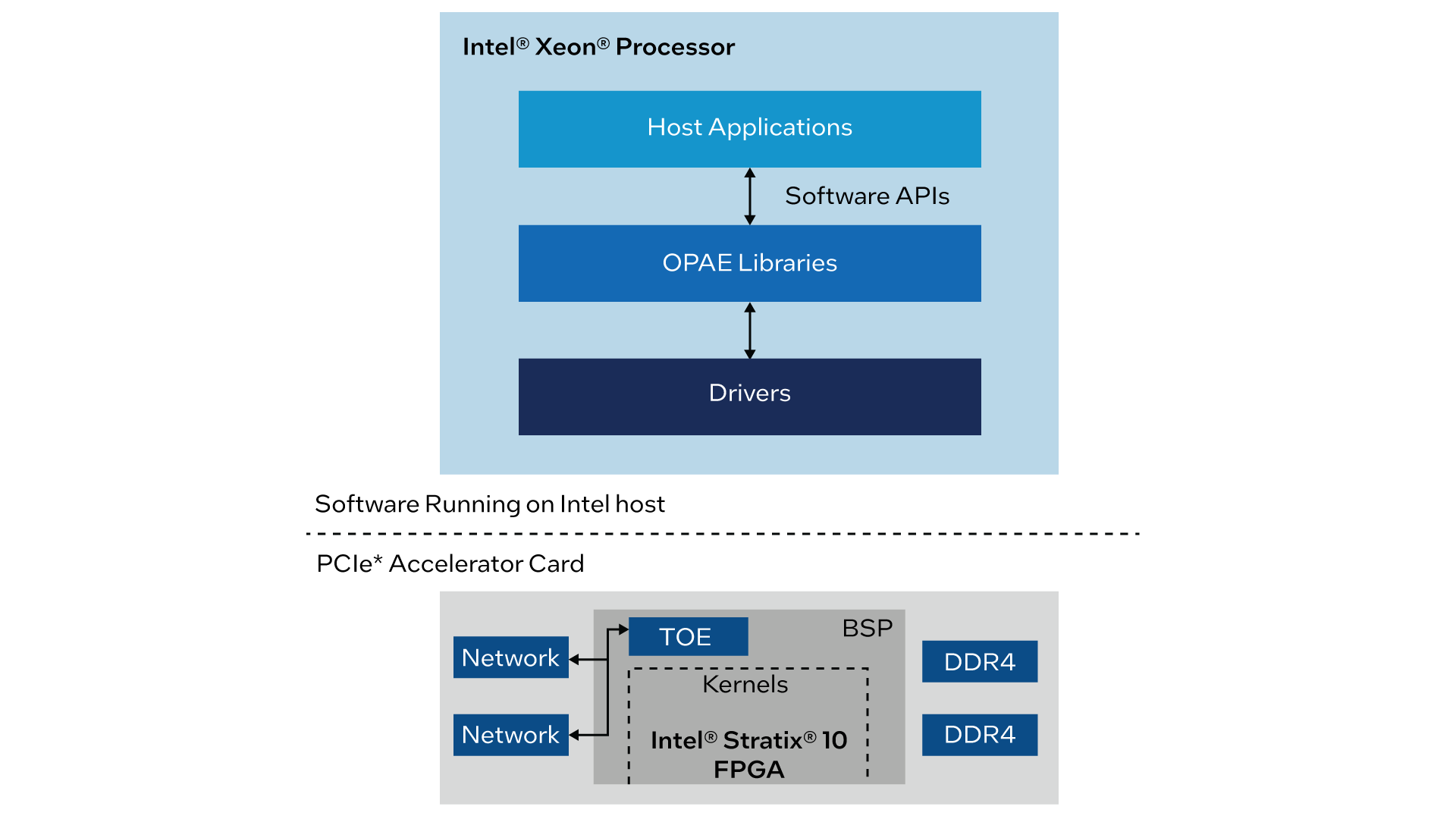
OFS 是一个开源硬件和软件基础设施,可提供快速启动基于 FPGA 的自定义主板或工作负载开发所需的所有关键设计、软件和基础设施组件。OFS 基础设施由 FIM(通常称为“shell”)和加速器功能单元 (AFU) 区域组成,其中 AFU 是一个用于工作负载开发的指定区域。借助 OFS,FPGA 主板或 FIM 开发人员可以利用开源基础设施或基础 FIM,根据目标应用或目标行业为其主板快速开发量身定制的 FIM。OFS 还附带了 oneAPI Accelerator Support Package (ASP),可用于提取 FPGA 硬件和设计流程。OFS 可节省开发人员的时间,提高 FPGA 各代间的可移植性,采用行业标准接口,并使用 oneAPI 提供可选的高层次设计流程。
FA728Q 加速卡现已推出,这是一款基于 PCIe 的高端 FPGA 加速板,可提供 32 GB 板载 DDR4 内存和三个 QSFP28 插槽,每个接口的速度可高达 100 GbE。FA728Q 加速卡还在 OFS 基础设施中采用了 oneAPI,从而客户可在 RTL 中实施其内核,或将 CPU/GPU 中的算法迁移到高级设计语言,包括 C/C++。英特尔 oneAPI Base Toolkit 还有助于将内核合成到 FPGA 资源并进行优化,从而进一步缩短上市时间。
此外,菲数科技已开始在基于英特尔® Agilex™ FPGA 的主板上进行开发,包括采用英特尔 Agilex 7 FPGA I 系列的 FA927S 卡和采用英特尔 Agilex 7 FPGA F 系列的 FA925E 卡。
FA927S 卡采用高达 116 Gbps 的高收发器速率和 PCIe 5.0 x16,并支持 Compute Express Link (CXL)。其面向带宽密集型应用,现已可用于基于 RTL 的开发。FA927S 卡将于 2024 年第一季度支持 OFS。
另一方面,FA925E 卡提供四个 8 GB 内存条和四个 4 GB DDR4 内存条,板载内存总容量为 48 GB。它专为具有较高外部内存容量和较高带宽要求的应用而设计。该卡全面支持 OFS,并将于 2023 年年底上市。 参见表 1,对三款加速卡进行比较。
表 1.比较表
|
|
|
|
|
|---|---|---|---|
| 功率 | 215 瓦 | 200 W | 150 瓦 |
| 散热要求 | 有源/无源(可选) | 有源/无源(可选) | 有源/无源(可选) |
| 外形 | 3/4 长、全高、双插槽 PCIe | 半长、全高、双插槽 PCIe | 3/4 长、全高、双插槽 PCIe |
| 网络接口 | 三个 QSFP28 端口:3 x 100 GbE / 40 GbE | 双 QSFP28 端口:2 x 100 GbE / 40 GbE | 双 QSFP28 端口 2 x 100 GbE / 40 GbE |
| 内存接口 | 4 x 8 GB DDR4,2,400 MHz,带 ECC | 4 x 8 GB DDR4,2,400 MHz,带 ECC | 4 x 8 GB 和 4 x 4 GB DDR4,2,400 MHz,带 ECC |
| PCIe 接口 | - | 5.0 x16 | - |
| 扩展接口 | - | 2 x8 纤薄 SAS 接口,用于 PCIe 4.0 扩展 | - |
| 管理端口 | 微型 USB | 微型 USB | 微型 USB |
| FPGA 设备 | 1SX280HN2F43E2VG | AGIB027R29A1E2VR3 | AGFB027R25A2E2V |



结果
菲数科技在 FA728Q 卡上实施的分载引擎 IP 功能在延迟和性能方面进行了优化,以满足 LLT 要求。在加速模式下,TCP 传输延迟小于 100 纳秒,确保时间关键型网络应用中稳定、低延迟的连接。表 2. 显示针对各种连接测得的延迟时间。表 3. 显示高带宽 PCIe 3.0 x16 和 DDR 接口。
| 规范 | 价值 |
|---|---|
| 最大 TCP/UDP 连接数 | TCP 为 63,UDP 为 63 |
| TCP TX 延迟(加速模式) | 15 个时钟 |
| TCP TX 延迟(非加速模式) | 46 个时钟 |
| TCP RX 延迟 | 32 个时钟 |
| UDP TX 延迟 | 针对 512 字节数据包为 42 个时钟,针对 128 字节数据包为 18 个时钟 |
| UDP RX 延迟 | 23 个时钟 |
| oneAPI 内核的环回延迟 | 18 个时钟 |
表 2.TCP/IP 分载引擎 (TOE) 规格
注:
1.一个时钟周期为 6.4 纳秒
2.TX 延迟从数据包 EOP 下降边缘一直计数到 XGMII TXC 中出现有效数据
3.RX 延迟从数据包 SOP 一直计数到 XGMII RXC 中出现有效数据
| 数据路径 | 带宽 |
|---|---|
| 主机写入内存 | 针对 8,192-KB 块为 8,287.68 MBps |
| 主机读取内存 | 针对 8,192-KB 块为 8,241.19 MBps |
| 内核写入内存 | 针对 4,096-MB 块为 16,909.6 MBps |
| 内核读取内存 | 针对 4,096-MB 块为 17,340.3 MBps |
表 3.每个接口提供的带宽
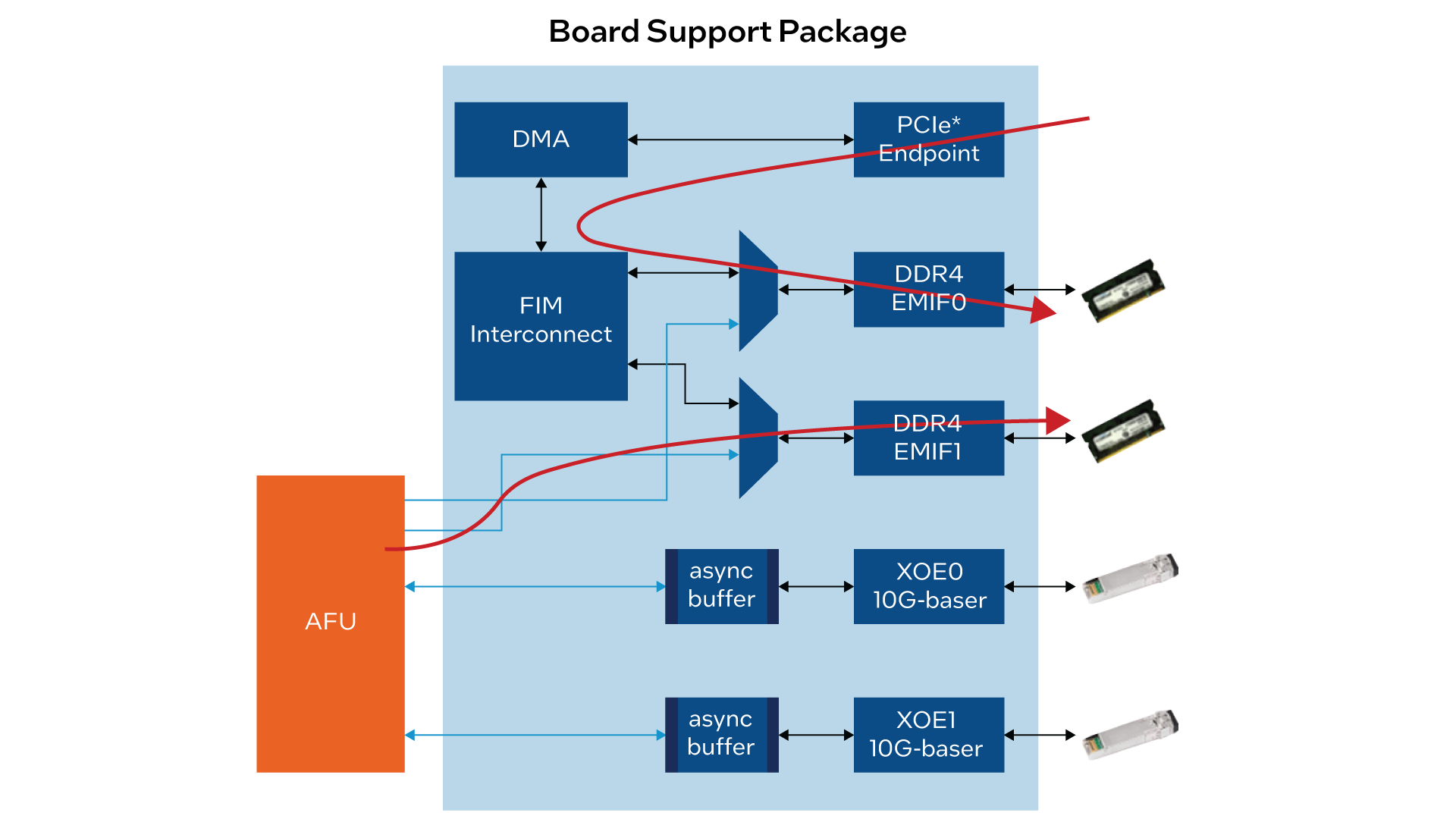
OFS 帮助我们更加轻松、快速地为客户搭建所需的加速平台,从软件 API 驱动程序到作为全套设备的底层硬件。
如何开始利用 OFS 进行 FPGA 加速
FPGA 开发人员可以借助 FA728Q 加速卡和启用 OFS 的主板,利用开源文档和源代码开始构建自定义工作负载。
下表概述了开发人员如何使用菲数科技加速板开始基于 FPGA 的工作负载开发。
| 利用 FPGA 加速优化您的工作负载 | |
|---|---|
| 第 1 步:选择主板 | 查看菲数科技推出的启用 OFS 的主板,即 FA728Q 加速卡 |
| 第 2 步:评估 OFS 开源资源 |
菲数科技将提供相应版本的 OFS 技术文档。 |
| 第 3 步:访问开源硬件和软件代码 |
菲数科技将提供相应的 OFS 软件和硬件代码。这是其 OFS 基础代码的特定发行版(由英特尔提供)。 |
| 第 4 步:利用 RTL 或 C/C++ 开发工作负载(使用 oneAPI) |
遵循 OFS RTL 流程 或 OFS 支持 oneAPI 内核的计算。利用 oneAPI 开发流程并使用 C/C++ 构建 FPGA 工作负载。 |